Reference-Collector: From Google Scholar List to Downloaded Papers
09 Mar 2026 My-toolboxNotes on a small toolbox to collect paper metadata and available PDFs from Google Scholar.
If you have ever tried to collect dozens (or hundreds) of papers from Google Scholar manually, you know the process is repetitive: copy title, search DOI, open publisher link, check whether PDF is available, and then repeat.
I recently published a toolbox to reduce this manual work:
![]()
I. What is Reference-Collector?
Reference-Collector is a pipeline that:
- Scrapes paper lists from a Google Scholar profile page or a “cited by” page
- Enriches records with Crossref metadata
- Tries PDF download with an arXiv-first strategy, then Sci-Hub fallback
- Exports a metadata table and a missing/failed report
In short: it helps convert an online Scholar list into a structured local reference workspace.

II. Why I built it
The main motivation is efficiency and traceability.
- Efficiency: avoid repetitive copy-paste/search steps when building literature sets
- Traceability: keep metadata and download results together under one working directory
- Follow-up friendly: unresolved items are written to
missing_or_failed.md, so manual checks are focused
The tool is especially useful when starting a new literature review and you want a fast first pass of what can be collected automatically.
III. Getting started
1. Install
python -m pip install -r requirements.txt
2. Run from a Scholar profile
python main.py --profile-url "google scholar profile page url" --workdir _results/demo
3. Run from a cited-by page
python main.py --cited-url "google scholar paper 'cited by' page url" --workdir _results/cited_demo
4. Metadata only (skip PDF download)
python main.py --profile-url "..." --no-download
5. Start from an existing sheet
python main.py --from-xlsx /path/to/metadata.xlsx --workdir _results/from_sheet
If Scholar asks for captcha, export cookies.txt from your browser session and pass it with --cookies-file.

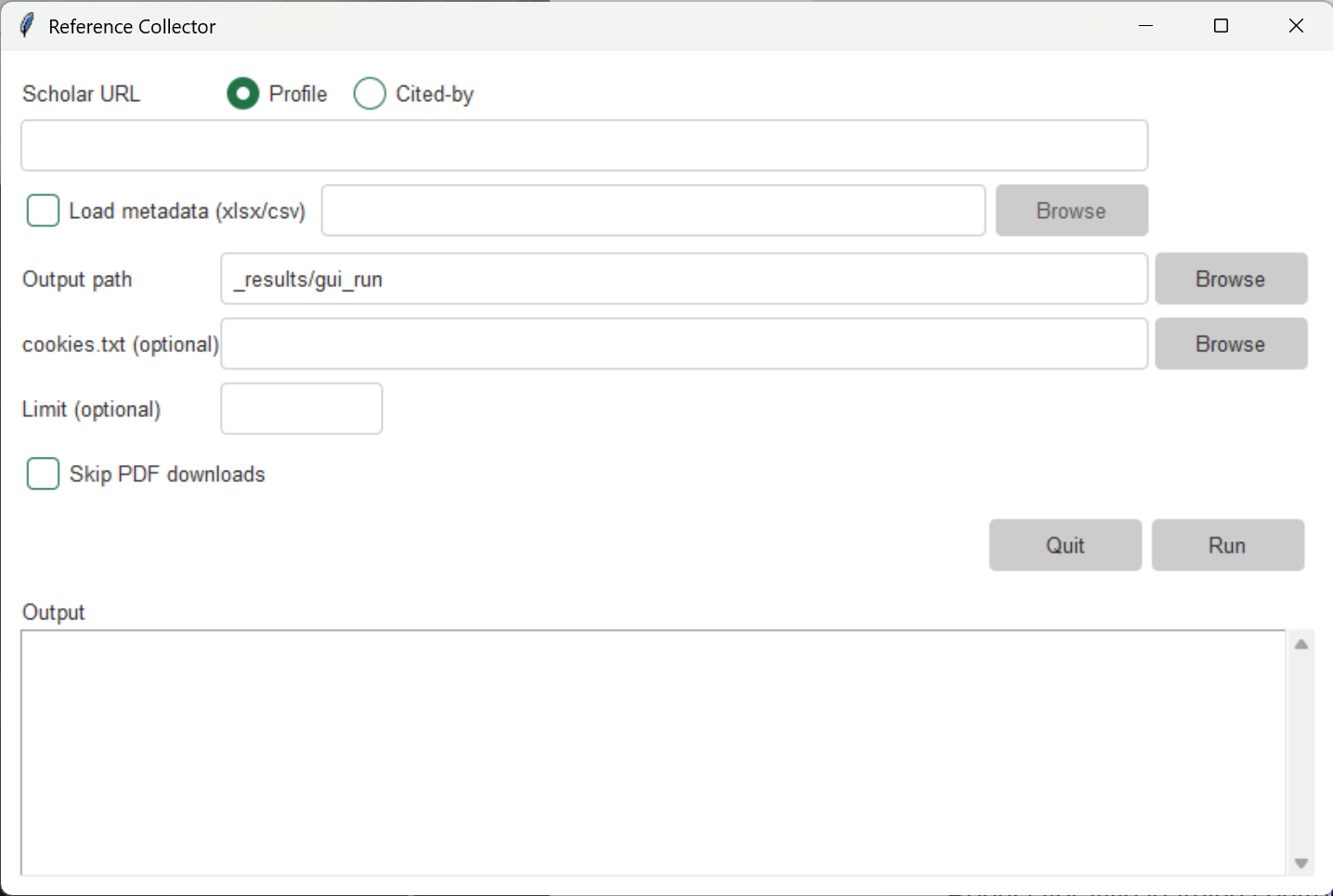
IV. What the outputs look like
The default outputs include:
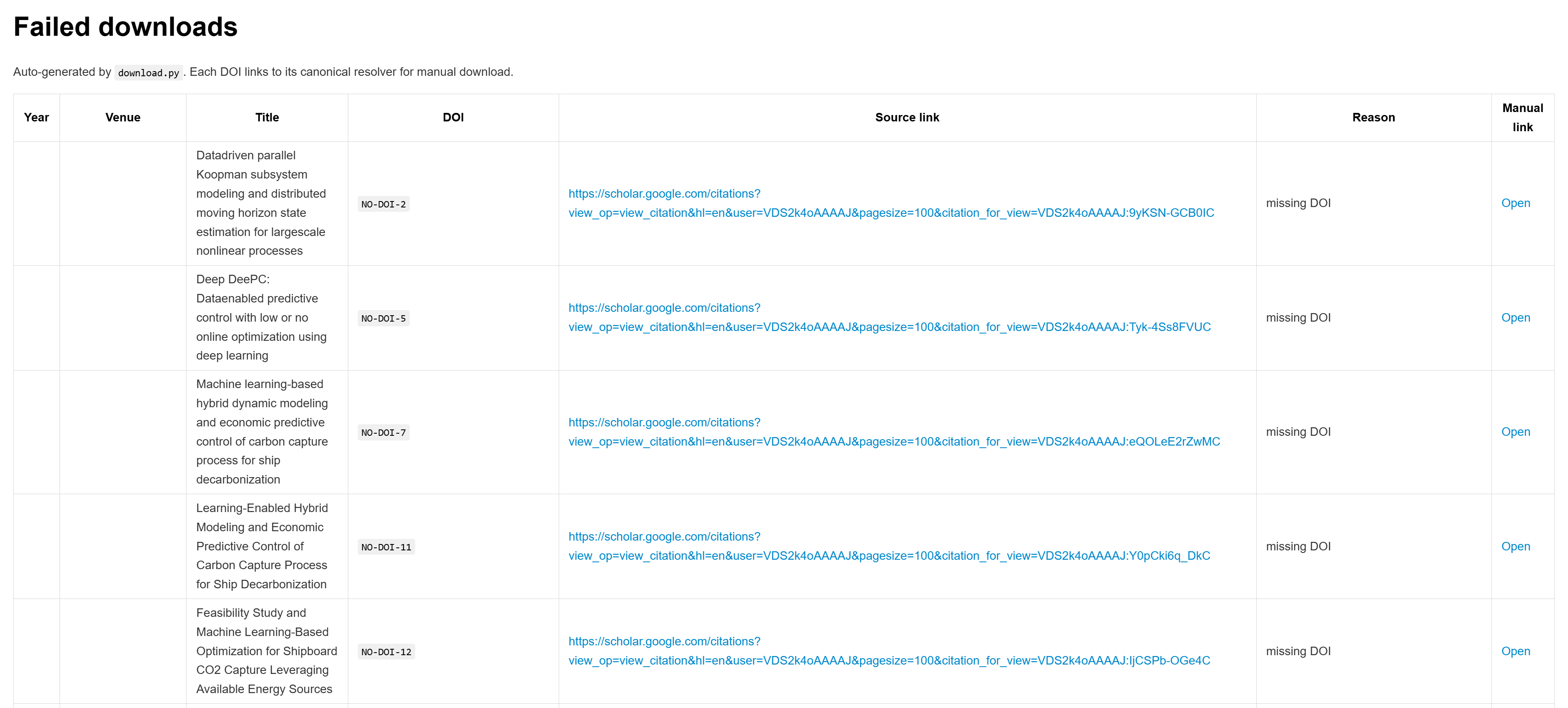
metadata.xlsxwith fields such as year, title, DOI, venue, and linksmissing_or_failed.mdlisting papers that could not be downloaded automatically
This means you can finish automated collection first, then spend manual effort only on unresolved items.
V. Notes
- The tool automates collection, but results still need human review for critical usage.
- Availability of downloadable PDFs depends on source accessibility (especially for newer papers).
If you are interested, check the project details and updates here:
https://github.com/Zhang-Xuewen/Reference-Collector
License
The project is released under the APACHE license. See LICENSE for details.
Copyright 2026 Xuewen Zhang
Licensed under the Apache License, Version 2.0 (the “License”); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an “AS IS” BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
Recent Posts
[30 Aug 2024] Paper: Deep DeePC
[29 Aug 2024] QYTool: A Utility Package for Research Needs
[25 Apr 2024] ModLinear: Linearize Nonlinear Models with Numerical and Symbolic Methods